

20250319使用Milvus数据库尝试将文件向量化
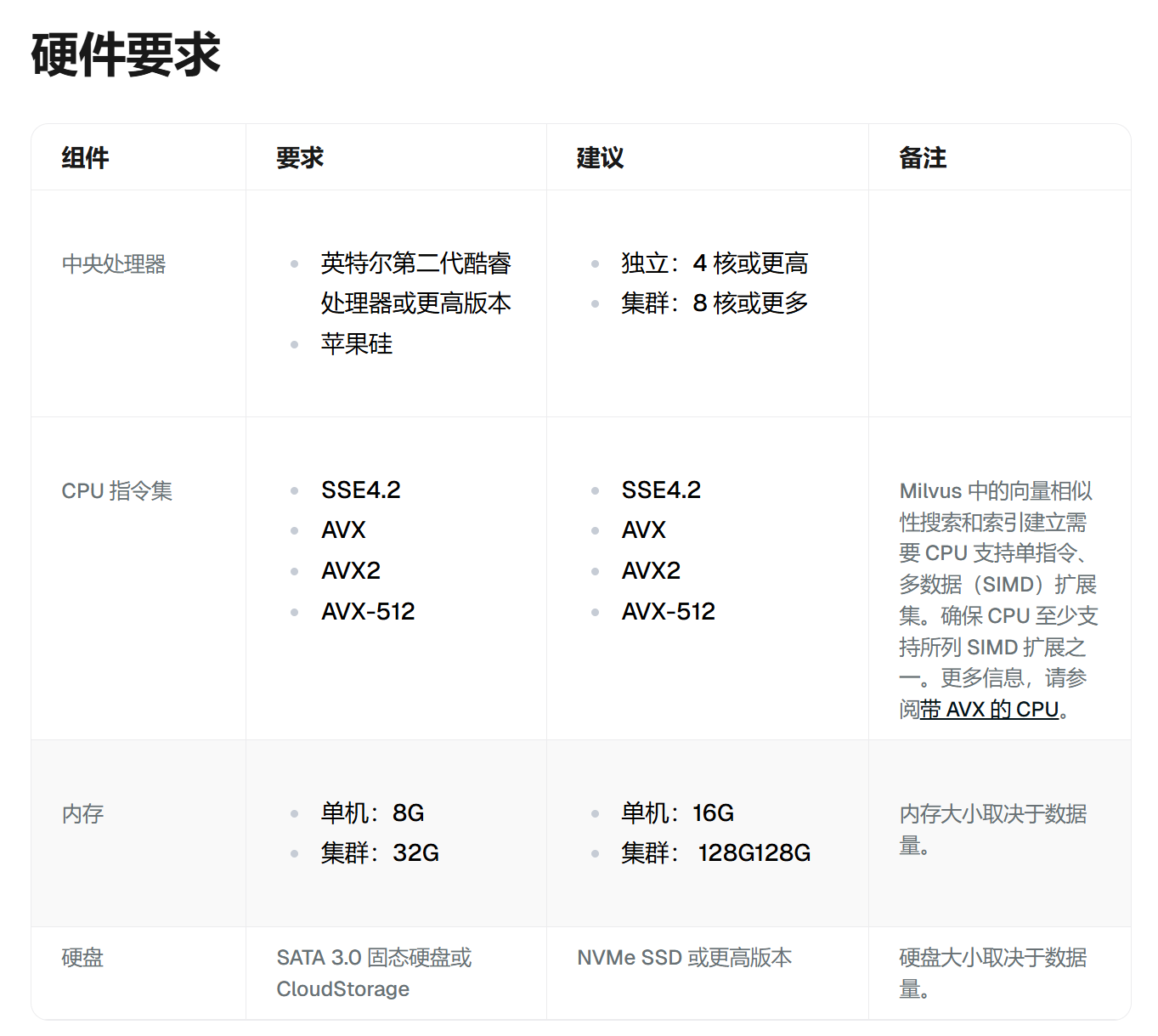
Milvus官网推荐的硬件要求
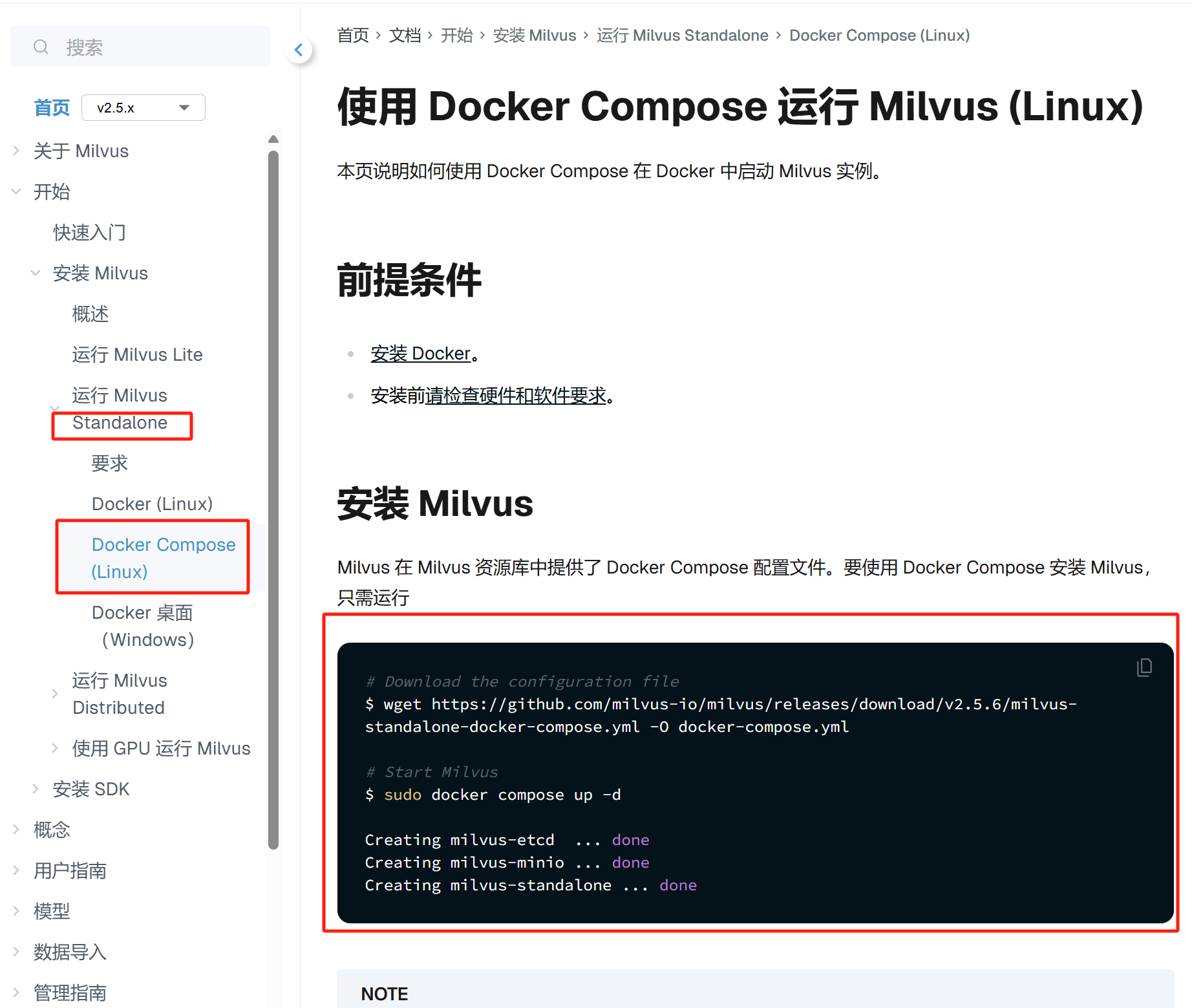
跟着官网文档安装
这里可能需要设置代理
export http_proxy="http://127.0.0.1:7897"
export https_proxy="http://127.0.0.1:7897"名词解释:
Rerank:重排序器是优化初始搜索结果排序的重要工具。重排器与传统的嵌入模型不同,它将查询和文档作为输入,直接返回相似度得分,而不是嵌入得分。该分数表示输入查询和文档之间的相关性。
Embeddings:将数据映射到高维空间,将语义相似的数据放在一起
密集嵌入:大多数嵌入模型将信息表示为数百到数千维的浮点向量。由于大多数维度的值都不为零,因此输出的向量被称为 "密集 "向量。例如,流行的开源嵌入模型 BAAI/bge-base-en-v1.5 输出的向量为 768 个浮点数(768 维浮点向量)。
稀疏嵌入:相比之下,稀疏嵌入的输出向量大部分维数为零,即 "稀疏 "向量。这些向量通常具有更高的维度(数万或更多),这是由标记词汇量的大小决定的。稀疏向量可由深度神经网络或文本语料库统计分析生成。由于稀疏嵌入向量具有可解释性和更好的域外泛化能力,越来越多的开发人员采用稀疏嵌入向量作为高密度嵌入向量的补充。
Milvus 是一个向量数据库,专为向量数据管理、存储和检索而设计。通过整合主流的嵌入和重排模型,您可以轻松地将原始文本转换为可搜索的向量,或使用强大的模型对结果进行重排,从而获得更准确的 Rerankers 结果。这种集成简化了文本转换,无需额外的嵌入或重排组件,从而简化了 RAG 的开发和验证。
全文搜索:优先处理与特定搜索词密切匹配的文档
混合搜索:跨connection搜索,通过主键关联
配置块缓存:大块缓存机制使 Milvus 能够在需要数据之前将其预先加载到查询节点本地硬盘的缓存中。这种机制缩短了将数据从磁盘加载到内存的时间,从而大大提高了向量检索性能。
Dify对接milvis
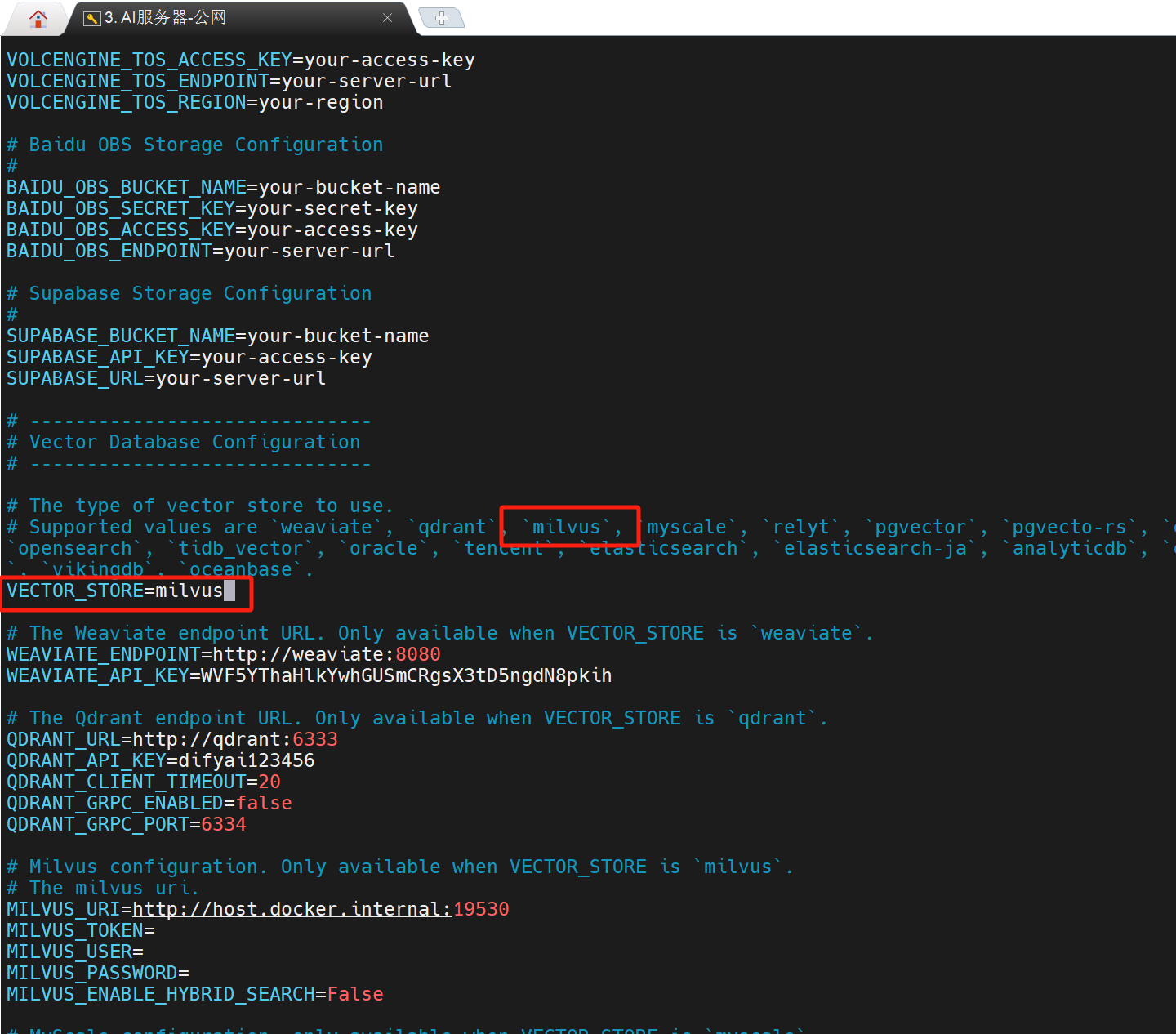
头好痒感觉要长脑子了 0.0




索引问题


概述
ANN 和 k-Nearest Neighbors (kNN) 搜索是向量相似性搜索的常用方法。在 kNN 搜索中,必须将向量空间中的所有向量与搜索请求中携带的查询向量进行比较,然后找出最相似的向量,这既耗时又耗费资源。
与 kNN 搜索不同,ANN 搜索算法要求提供一个索引文件,记录向量 Embeddings 的排序顺序。当收到搜索请求时,可以使用索引文件作为参考,快速找到可能包含与查询向量最相似的向量嵌入的子组。然后,你可以使用指定的度量类型来测量查询向量与子组中的向量之间的相似度,根据与查询向量的相似度对组成员进行排序,并找出前 K 个组成员。